CPU optimizations
The goal of this article is to cover some cpu optimizations from java developer’s view. We will talk about:
- Branch prediction
- Cache levels
- False sharing
- Prefetching
- Loop unrolling
Branch prediction
Let’s look at the next code:
private static int countOfElementsLessThen(final int value, final int[] array){
int result=0;
for(int anArray : array)
if (anArray < value)
result++;
return result;
}
The method looks pretty good and at the first sight, there is nothing to worry about. Yet this point is delusive.
We can estimate the average time taken for invocation the method (for this purpose JMH benchmark is used). Let’s take an array that contains numbers. Yet in the first case, the array is unordered and in the second one, the array is sorted. Surprisingly, the results of our estimations are different significantly.

| Benchmark | Mode | Count | Score | Error | Units |
|---|---|---|---|---|---|
| sorted array | avgt | 10 | 0.631 | ± 0.035 | ms/op |
| unsorted array | avgt | 10 | 3.957 | ± 0.142 | ms/op |
As we can see, type of input array matters. The thing is modern cpu executes instructions not sequentially. They do it with so-called Instruction pipelining. Thus, an instruction goes through several stages and, as the rule, different instructions take place on different stages at the same time.
The picture below helps understand how it works more clearly.

However, the workflow of execution the method countOfElementsLessThen does not let use the instruction pipelining
effectively. Each command needs the result of the execution the previous instruction in order to figure out what the
instruction will be executed next. It is slow and there is an optimization for this case . It is called branch
prediction. The point of it is trying to predict in which way the workflow will go next time and executing it. At the
moment, when CPU has all necessary information to check which branch of the workflow is right. There are two possible
scenarios. The first one is CPU prediction is incorrect, so CPU rollbacks the execution result and execute the
instructions of the correct branch. The second scenario is the prediction is right, so CPU just uses the current
execution result.
I suppose, CPUs predictions are not too sophisticated. In case with the method countOfElementsLessThen, CPU decides to
execute instructions in if block based on statistical measures about previous executions. By this way, all instructions are
executed sequentially. At some loop iteration when a current number of array is bigger than a parameter value,
prediction can be changed. This explanation is quite naive and simplified.
Cache levels
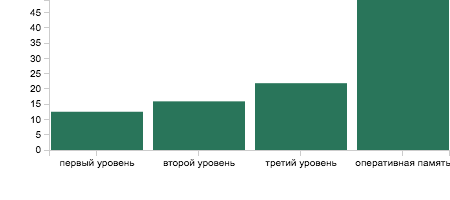
CPU is very performance, and the difference between time to access to RAM memory and CPU registers is enormous. The picture below shows it:

In order to smooth the difference, CPU has several cache levels. As the rule, there are 3 levels: the first level cache, the second level cache and the third level cache. Each level has different capacity and access latency. For sure, it can range from a manufacturer and platform. For example, my laptop has the next configuration:
| Cache level | Capacity |
|---|---|
| First level | 256KB |
| Second level | 1MB |
| Third level | 6MB |
Also, it should be noted that each CPU core has the first and the second level caches, but the third level cache is only one for all cores.
I don’t want to show a code due to it is quite cumbersome. If you wish to check it, it is here The results I have got is below:
| Benchmark | Mode | Count | Score | Error | Units |
|---|---|---|---|---|---|
| CpuCacheLevelBenchmark.firstCacheLevel | ss | 10 | 12.528 | ± 1.804 | ms/op |
| CpuCacheLevelBenchmark.secondCacheLevel | ss | 10 | 15.938 | ± 1.361 | ms/op |
| CpuCacheLevelBenchmark.thirdCacheLevel | ss | 10 | 21.886 | ± 6.798 | ms/op |
| CpuCacheLevelBenchmark.ramCacheLevel | ss | 10 | 49.141 | ± 11.880 | ms/op |
The tendency is clear - the higher cache level, the more latency we get.
False sharing
First of all, I would like to say that it is not an optimization. False sharing is an effect that can affect your
program performance significantly. To some extends, it follows from the previous optimization.
All data take place in caches in form of cache lines. Sometimes, we can face the situation where we are extremely
unlucky and one cache line contains non-related data. Different threads update the data and CPU needs to sync caches of
different cores.
To make the explanation clear, suppose there is an object:
Tuple unoptimizedTuple = new Tuple(){
private volatile int firstValue;
private volatile int secondValue;
//other methods
};
In case, if one tread updates field firstValue and another one updates field secondValue of the same object, we can
observe the false sharing effect. To avoid it, we can align an object size of the object with respect to cache lines.
After it, the fields take place in different cache lines. There is one of possible solutions:
Tuple optimizedTuple = new Tuple(){
private volatile int firstValue;
//non-used fields for aligning
private long p1,p2,p3,p4,p5,p6,p7,p8;
private volatile int secondValue;
//other
};
Let’s compare the difference:

| Benchmark | Mode | Count | Score | Error | Units |
|---|---|---|---|---|---|
| FalseSharingBenchmark.invokeWithOptimization | ss | 10 | 62.584 | ±6.625 | ms/op |
| FalseSharingBenchmark.invokeWitoutOptimization | ss | 10 | 289.808 | ±26.294 | ms/op |
Prefetching
As I said early, CPU uses cache to minimize the latency of access to RAM. Initially, CPU tries to get data from the first level cache and in case if the data is absent, CPU tries to do the same with higher level caches. Eventually, if data is not found in the caches (cache miss), CPU loads it from RAM. Obviously, the process of fetching data from caches and especially RAM is not fast. In order to avoid it, CPU uses prefetching.
The logic of the work is pretty simple. The data that is closed to used data is highly likely to be required coming soon. Therefore, CPU should care about existence of this data in a cache.
We can observe the effect of the optimization when we use a linked and array list. An array is allocated sequentially in a memory and there is no problem for CPU to detect the next memory segment for loading. However, prefetching does not work with linked lists 😕. Thus, each node of linked list refers to an arbitrary segment of memory.
The graph and table depict the difference:
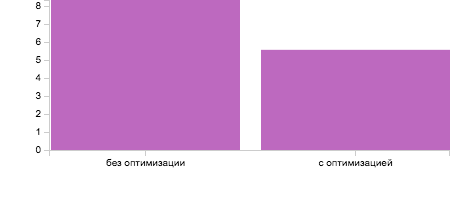
| Benchmark | Mode | Count | Score | Error | Units |
|---|---|---|---|---|---|
| PrefetchingBenchmark.invokeWithOptimization | avgt | 10 | 5.570 | ± 0.229 | ms/op |
| PrefetchingBenchmark.invokeWithoutOptimization | avgt | 10 | 8.341 | ± 0.206 | ms/op |
Loop unrolling
The last CPU optimization that we are talking about in this article is loop unrolling. The essence of it is quite simple. The modern CPUs can apply vectorization techniques to improve performance. If CPU supports it, it has extended registers. For example, CPU that does not, has registers with 8 or 32 bit capacity, but CPU that does, has registers with 128 or 256 bit. Thus, the last one can store a set of data and work with them like it is one value at once.
Let’s look at the code:
int result = 0;
for (long v : array)
result += v
The code is quite trivial. It sums up all values of an array with odd size (I set to 1 000 001). In my case, CPU doesn’t use vectorization instructions, so we can help it by slightly rewrite the code.
int result = 0;
for (int i = 0; i < array.length - 1; i += 4)
result += (
array[i]
+ array[i + 1]
+ array[i + 2]
+ array[i + 3]
);
result += array[array.length - 1];
After changes, CPU applies vectorization instructions. The results prove our suggestions:
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| LoopUnrollingBenchmark.invokeWithOptimization | avgt | 10 | 0.390 | ± 0.021 | ms/op |
| LoopUnrollingBenchmark.invokeWithoutOptimization | avgt | 10 | 0.440 | ± 0.038 | ms/op |
That’s all. Thank you for reading. I hope the article will come in handy.
![]()